|
SQL Server 7
Administration
Installation and Configuration
Hardware/Software
Requirement
|
Computer
|
-
Intel Pentium 166
-
DEC Alpha
|
|
Memory
|
|
|
Harddisk
|
|
|
Filesystem
|
|
|
OS
|
-
NT Server Enterprise
Edition (SP4 or later)
-
NT Server 4.0 (SP4 or
later)
-
NT Workstation 4.0 (SP4
or later)
-
Windows 95/98
|
|
Browser
|
Internet Explorer 4.01
with SP1 or later |
|
Default Path
|
C:\mssql7\ |
Network Support
-
Named Pipes (not on
W95)
-
TCP/IP Sockets
(TCP-Port 1433)
-
Multiprotocol
(NWLink,
TCP/IP, Named Pipe, Windows Sockets, Encryption)
-
NW-Link (IPX/SPX)
-
AppleTalk ADSP
-
Banyan VINES
|
Note : |
For
enabling encryption modify registry on SQL Server and
on client
|
|
|
Default
setting : Multiprotocol
|
Memory Allocation
-
Dynamic Memory Allocation
(Default setting)
-
Fixed Memory Allocation
(Specify min server memory / max
server memory )
-
Use sp_configure or MMC
(==> MMC : SQL Server -> Right
Click -> Properties -> Memory) to modify it
-
Use the set working set
size option to reserve physical memory space for
SQL Server that is equal to the server memory setting (1
enables it, 0 disables it -> default setting).
Enabling set working size and configuring
a max server memory setting might be
useful if other applications will be or are competing for
memory resources with SQL Server.
Unattendend Installation
|
Command file
|
Setup file
|
Installation
|
|
sql70cli.bat
|
sql70cli.iss
|
SQL Server
management tools
|
|
sql70ins.bat
|
sql70ins.iss
|
Typical
installation SQL Server (NT Local System
account)
|
|
sqlcst.bat
|
sql70cst.iss
|
Custom SQL Server installation (NT Local System
account) with all typical
components
|
Path: C:\mssql7\install
Create
Installation Script :
setupsql.exe k=Rc (Setup-file is stored as setup.iss)
Uninstall : isunist.exe -f
<isunist.isu> -cC:\mssql7\sqlsun.dll -y
-a
License
|
Per-seat
licensing
|
License for
each computer
|
|
Per-server
licensing
|
Numbers of
Licenses on server (N licenses = N
connections)
|
|
Internet
Connector licensing
|
License for
using SQL Server through IIS or MS Transaction
Server
|
Character
Set, Sort Order, Unicode Collation
Care must be taken when
configuring the character set, sort order, or unicode
collation. Changing any of these requires rebuilding
the master database and reloading data.
-
Default Character Set:
Code Page 1252
-
Default Sort Order:
Dictionary, case insensitive
-
Default Unicode Collation:
General Unicode, case insensitive, width
insensitive, Kana
insensitive
Default Installation
|
SQL Server
services
|
-
MSSQLserver
-
SQLServer Agent
-
MS DTC
-
Microsoft Search
|
|
Management
tools
|
Tools |
|
Databases
|
-
master, model, msdb,
tempdb (System-DBs)
-
pubs, northwind
(User-DBs) |
|
Directories
|
C:\mssql70\binn
|
|
Default
startup
|
Default startup options
are written to the
registry |
|
Default
security mode
|
Mixed mode (NT security
and SQL security) |
|
sa login
account
|
sa without password (SQL
security) |
|
SqlAgentCmdExec account
|
local user account (NT
security), used for jobs and
services |
The SQL Server
default databases
|
master
|
Information about logins,
stored procedures, pointer to primary data file for
every database
|
|
model
|
Provides a template or
prototype for new databases. Contains the system
tables which belong in every database. Items that are
to appear in all new databases should be placed
here.The size is approx. 1.5 MB after
installation.
|
|
tempdb
|
Provides storage for
temporary tables and other temporary storage needs
such as intermediate results of GROUP BY, ORDER BY,
DISTINCT and cursors.The size is approx. 2.5 MB after
installation.
|
|
msdb
|
Supports the SQL Agent
Service, including information about jobs, alerts,
events and replication. Also history about all
backup/restore. The size is approx. 8.5 MB after
installation.
|
|
Pubs/Northwind
|
Template databases for
learning (pubs ~2MB, northwind ~8.5
MB)
|
Some system tables
|
sysdatabases
|
Databases on
SQL Server
|
|
sysdevices
|
Available
database and disk devices
|
|
sysxlogins
|
User
accounts
|
|
sysmessages
|
System error
messages
|
|
sysservers
|
Remote
servers
|
|
sysmessages
|
Error
messages
|
|
sysoperators
|
Administrative
personnel information, including email addresses and
pager numbers
|
|
sysalerts
|
User-defined
alerts
|
|
backupfiles
|
List of
backupfiles
|
|
backupset
|
List of
backups
|
|
sysjobs
|
Jobs
|
Information Schema Views
|
SELECT * FROM
information_schema.table
|
List of tables
in the database
|
|
SELECT * FROM
information_schema.colums
|
List of colums
in the database
|
|
SELECT * FROM
information_schema.table_privileges
|
Security
information in database
|
|
SELECT
user_name(<id>)
|
Returns user's
name
|
Starting/Stopping SQL
Server Services
-
SQL Server Service
Manager
-
SQL Server Enterprise
Manager
-
Services in Control
Panel
-
net start/pause/stop
mssqlserver
-
net start/pause/stop
mssqlserver
-
CMD : C:> sqlstart.exe -f
(start SQL Server with minimal configuration, output to
console)
Note : Pausing
doesn't accept new connections, already connected users
are unaffected
Registry |
HK_LM\software\microsoft\MSSQLServer\
|
Clustering Service
To run SQL
Clustering Service setup on a new SQL Server 7.0
installation using the Failover Setup Wizard
-
Identify the disk names
controlled by the primary node of the cluster on which
you will install SQL Server.
-
To stop any additional
services such as IIS, MTS, MSDTC, and Exchange that may
be running or installed by default on the cluster,
right-click the resource; then click Take Offline.
-
Run Setup.exe from the SQL
Server 7.0 directory of software compatible with your
processor architecture.
-
Specify a shared drive
controlled by the primary node of the cluster where you
want SQL Server to be installed, in the SQL Server
Installation Path dialog box, and in the Master Database
Installation Path dialog box.
Named Pipes is required only
for installing SQL Server and SQL Server Cluster Setup.
If you want to use another network protocol for normal
business operations, ensure that it is also selected.
-
Start SQL Server, check the
installation, and then stop SQL Server. The installation
program will install the necessary SQL Server management
tools to the local drive. In the event of a failover,
you will be able to manage the SQL Server virtual server
through normal graphical user interface (GUI)
operations.
-
On the Start menu, point to
Programs/Microsoft SQL Server 7.0/Failover, and then
click Failover Cluster Wizard.
-
Select options (Virtual
server, 'sa' Password, IP address, virtual server
name)
-
Confirm your choices, or
click Backup to make the necessary corrections.
Changing
Sort Order, Character Set, Unicode Collation after
Installation
-
Backup object definitions you
wish to preserve by using Enterprise Manager to create
scripts.
-
Export data using DTS or
BCP
-
Rebuild master database using
rebuildm utility, specifying new sort
order, character set, or unicode collation. (You
will need the installation CD)
-
Create databases using EM or
CREATE DATABASE statement
-
Create objects using scripts
generated in step 1.
-
Import data using BCP or
DTS.
Upgrading to SQL 7
Configuring and
Managing Security
Access to SQL granted by means of
login entry in sysxlogins table in Master database.
User must have either a mapping that associates an NT
account (group or users) to an entry in sysxlogins in the
case of NT authentication mode or have a separate login
entry in the case of SQL Server authentication. Access
to SQL through entries in sysxlogins does not give access to
databases. Database permissions are separate from SQL
server logins.
-
NT Authentication mode (SQL
6.5 : Integrated Mode). Requires use of Named Pipes
or Multiprotocol. User must be authenticated by NT
before connection to SQL is allowed. Sometimes
referred to as "trusted connection". User does not
have to provide separate credentials to access SQL
-
SQL Server Authentication (SQL
6.5 : Standard Mode). User has to supply SQL login
credentials. Windows 9x always uses Standard
Security.
Security
Settings
-
SQL Server and Windows
NT (Mixed Mode) -> NT Authentication and SQL
Server Authentication. Useful in situations where
there is a mix of clients, such as Unix hosts or Netware
clients, that cannot authenticate to NT.
-
Windows NT
only -> Only NT Authentication
==> MMC :
SQL Server -> Right Click -> Properties ->
Security
You can explicitly deny access
to SQL server to an NT account. To deny access
to a SQL Server account, remove login or don't create
it.
Default Login
-
sa (no password as default),
Superuser for SQL Server
-
BUILDIN\Administrator,
Superuser for SQL Server
==> MMC :
SQL Server -> Security ->
Logins
Permission are applied to entries
in the sysusers table and stored in the sysprotects table of
the current database.
Database Access
In order to gain access to a
database, you must have a username in database mapped to a
SQL Server login or a 'guest' account must
exist in database. Database username and login name do
not have to match, although they should for ease of
administation. To create a user in a database, use
Enterprise Manager or the SQL7 stored procedure "sp_grantdbaccess". To revoke database access, use
"sp_revokedbaccess". Many SQL 6.5 commands, such as
"sp_adduser" are still supported.
Guest
User
The guest user account
allows a login without a user account to access a
database. A login assumes the identity of the guest
user when all of the following conditions are met:
-
The login has access to SQL
Server, but does not have access to the database through
his or her own user account.
-
The database contains a
guest user account.
Permissions can be applied to
the guest user as if it were any other user
account. The guest user can be deleted and added to
all databases except master and tempdb,
where it must always exist. By default, a guest
user account does not exist in newly created
databases. However, if guest is
added to the model database, every subsequently created
database will have this account.
Roles
Analogous to NT Groups, except
for the fact that a member of any role can add other users
to same role. Roles replace the use of SQL 6.x
groups. Unlike SQL groups, users can be members of
multiple roles and roles can be nested. Aliases, which
are used to impersonate a user in a database, are still
supported. There are 4 types of roles:
==> MMC :
SQL Server -> Security -> Server
Roles
|
sysadmin
|
Perform
any activity
|
|
serveradmin
|
Configure
server-wide settings
|
|
setupadmin
|
Install
replication(?). Set up linked
servers.
|
|
securityadmin
|
Manage and
audit server logins
|
|
processadmin
|
Manage SQL
Server processes
|
|
dbcreator
|
Create and
alter databases
|
|
diskadmin
|
Manage
disk
files
|
|
public
|
Maintain
all default permissions. Every DB has a
public role. All users are members.
Can't be removed.
|
|
db_owner
|
perform
any database role activity
|
|
db_accessadmin
|
Add,
remove database users, groups and
roles
|
|
db_ddladmin
|
Add,
modify, or drop database objects. Run DDL
commands, except those that modify
permissions.
|
|
db_security admin
|
Assign
statement and object permissions
|
|
db_backupoperator
|
Backup
database
|
|
db_datareader
|
Read data
from any table
|
|
db_writer
|
Add,
change , or delete data from tables
|
|
db_denydatareader
|
Cannot
read data from any table
|
|
db_denydatawriter
|
Cannot
change data from any
table
|
-
Used to restrict access to
database through an application. Scope of role
is the database.
-
Application roles have no
members.
-
Activated by lauching an
application using sp_setapprole stored
procedure. Password required for activation
application role.
-
Users lose all permissions
in database, except those of the application role and
those given to public. Has no effect on user
permissions in other databases.
-
Role is only deactivated
for user only when the user disconnects from
SQL.
Permissions
Permissions in databases are
cumulative, except where a permission has been explicitly
denied (analogous to no access NTFS permission).
Implicit user permissions, such as those that are acquired
through role membership or those that are implicitly given
to Database Object Owners, can not be directly viewed.
Database Object Owners have all permissions on objects they
create and can grant, revoke or deny permissions to
all users, including the Database Owner, on these objects.
Types of
permission
Permissions apply to statements
and objects. Statement permissions give users the
ability to execute Transact-SQL commands, such as CREATE
DATABASE. Object permissions give users the ability to
do something, such as viewing or updating information in a
table or executing a stored procedure.
-
Statement Permissions: create
database, create table, create view, create rule, create
default, backup database, backup log
-
Object Permissions:
Select, insert, update, delete, references, execute.
Select, insert, update, delete and references can be
applied to tables and views, select, update,
references to columns, and execute to stored
procedures.
-
Predefined (implicit)
permissions apply to fixed roles or object owners.
Assigning Permissions
-
Grant (can perform
action)
-
Deny (Cannot perform action
and cannot overridden)
-
Revoke (Cannot perform action
but can be overridden)
USE
<database>
GRANT {ALL | statement[,...n]}
ON <table>
TO security_account[,...n] USE
<database>
DENY{ALL | statement[,...n]}
ON <table>
TO security_account[,...n] USE
<database>
REVOKE {ALL | statement[,...n]}
ON <table>
FROM security_account[,...n]
==> MMC :
SQL Server -> Database -> Tables ->
Right Click -> Properties ->
Permission
Permissions can be granted to
views without having to grant permissions to the
underlying tables that comprise the views, provided the
ownership chain is not broken. Users who have
Execute permissions on stored procedures do not need to be
granted permissions to modify or view the data that the
stored procedure needs access to.
Ownership Chains
Objects, such as views, have
owners. When a single owner creates a series of
dependent objects, such as view that in itself is created
from another view or views, and owns all the objects in the
chain, there is a single ownership chain. For
example, when the dbo creates View1 and then creates View2
that is based on View1, there is a single chain. If
the dbo, however, grants the permission to create a view to
another user and that user creates a third view based on
View2, the ownership chain is broken: the user does
not own the object that his or her view depends on.
SQL server will check permissions only once if there is a
single ownership chain--on the view itself and not on the
objects it may depend on. However, if there is a
broken ownership chain, SQL will check permissions on all
the objects in the chain where there is a change in
ownership. So, if Mary grants Joe the select
permission on View3 and Mary does not own the objects that
View3 depends on, Joe's permissions will be checked on those
objects. If Joe does not have permissions on the upper
objects in the chain, his query will fail. Use
sp_changeobjectowner to change ownership of objects in
database.
Recommendations
-
Use Mixed Mode for non-trusted
or Internet Clients
-
Use sysadmin role rather the
sa account
-
Remove NT accounts first, the
SQL Server accounts
-
dbo user should own all
objects to prevent broken ownership chains
-
Use stored procedures and
views to simplify security
Managing and
Maintaining Data
Database
-
Data (*.mdf /
*.ndf)
-
Log (*.ldf)
-
Data are stored in 8kB pages
-
Extents are the basic unit in
which space is allocated to tables and indexes, an extent
is 8 contiguous pages (64 KB)
-
Rows cannot span pages (Max.
8060 bytes per row)
-
Table and indexes are stored
in extents. An extent is 8 contiguous pages (64kB)
-
Default size of transaction
log is 1MB (increments by 1MB)
Locking
|
Types of Locking
|
|
Shared
|
Allows
concurrent transactions to read (SELECT) on datas,
not modify
|
|
Exclusive
|
It prevents
others from viewing or modifying datas
|
|
Update
|
It prevents
others from modifying datas during
update
|
|
Intent
|
Indicates that
SQL Server wants to acquire a shared or exclusive
lock on some of the resources 'lower' down in the
hierarchy
|
|
Lock
Types
|
|
RID
|
Row ID. Used
to lock a single row within a table.
|
|
Key
|
Row lock
within an index.
|
|
Page
|
8 kilobyte
(KB) data page or index page.
|
|
Extent
|
Contiguous
group of eight data pages or index
pages.
|
|
Table
|
Entire table,
including all data and indexes.
|
|
Database
|
Database.
|
Create
databases
CREATE DATABASE
Sales
ON
( NAME = Sales_dat,
FILENAME = 'c:\mssql7\data\mydb_data.mdf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 5 )
LOG ON
( NAME = 'Sales_log',
FILENAME = 'c:\mssql7\data\mydb_log.ldf',
SIZE
= 5MB,
MAXSIZE = 25MB,
FILEGROWTH
= 5MB )
==> MMC :
SQL Server -> Databases -> Right click
-> New Database
Dropping
database
DROP DATABASE
publishing
==> MMC :
SQL Server -> Databases -> Right Pane ->
Click database -> Right Click ->
Delete
Filegroups
ALTER DATABASE
my_database
ADD FILEGROUP mydb_group ALTER
DATABASE my_database
ADD FILE
(NAME = studer2,
FILENAME
= 'C:\mssql7\data\mydb_data2.ndf',
SIZE = 4)
TO
FILEGROUP mydb_group
NOTE : If no
'FILEGROUP' specified this database is added to the
PRIMARY group
Data Loading
-
DTS
DTS (Data Transformation
Services) Designer makes it easy to import, export, and
transform heterogeneous data.
==> MMC :
SQL Server -> DTS
or
==> MMC
: SQL Server -> Database -> Right Click
-> All Task -> Import/Export Data
Database
Scripting
==> MMC :
SQL Server -> Tools -> Database
Scripting)
You can generate Transact-SQL
statements to create objects identical to those currently
in your database. This is useful if you want to create
objects on other servers with the same schema as those in
your original database.
Estimate the amount of
data in tables
-
Calculate number of bytes in a
row (bytes in the row / avarage variable-lenght colums)
-
Determine number of rows in a
data page (dividide 8060 by the total bytes in the row /
round it)
-
Divide numbers of rows in a
table by numbers of rows in a data page
Note : A row
cannot be larger than one page
Performance
Considerations
-
Use RAID to improve
performance or fault tolerance (use RAID disk striping
over filegroups)
-
Eliminate disk drive
contention (use different disks for database and
transaction log)
-
Symplify Backups by using
filegroups (use filegroups to place database objects on
seperate disks)
Using the Web Assistant
Wizard
The Web Assistant Wizard
generates HTML files by using Transact-SQL queries, stored
procedures, and extended stored procedures. HTML files,
also known as Web pages, can be viewed by using an HTML
browser. HTML files are resources for displaying
information on the Web and on internal
networks.
-
Schedule a task to update a
Web page automatically.
-
Publish and distribute
management reports
-
Publish server reports with
information about who is accessing the server currently,
which locks are being held, and by which users.
-
Publish information outside of
SQL Server using extended stored procedures.
-
Publish server jump lists
using a table of favorite Web sites.
Web Assistant Wizard
-
Start the Web Assistant
Wizard, then select the database data to publish.
-
Specify the frequency of Web
page updates.
-
Name the HTML file, then
specify where it is to be published.
-
Include some basic HTML
formatting for the titles and tables using the
formatting screens.
-
Add optional URLs to
complete your page.
Backing Up Databases
Backup contains
Who performs
backups
-
sysadmin fixed server
role
-
db_owner fixed database
role
-
db_backupoperator fixed
database role
Where to store
backups
When you have to
backup
-
After modifying master
database (eg. create database, alter database or drop
database)
-
After modifying msdb database
(eg. sp_logdevice which alters transaction log)
-
After modifying model database
(eg. sp_addserver, sp_dropserver and sp_addlinkedserver)
-
After creating databses
-
After creating indexes
-
After clearing transaction log
(eg. BACKUP LOG WITH NO LOG or BACKUP LOG WITH TRUNCATE
ONLY)
-
After performing nonlogged
operations (eg. bcp, SELECT ... INTO, WRITETEXT,
UPDATETEXT)
The BACKUP statement
cannot be performed at the same time as these operations
-
DBCC CHECKALLOC
-
DBCC SHRINKDATABASE
-
bcp
-
SELECT INTO
-
File manipulation
Creating backup
-- Create the
backup device for the full MyNwind backup.
USE master
EXEC
sp_addumpdevice 'disk', 'MyNwind_2',
'c:\mssql7\backup\MyNwind_2.dat'
--
Back up the full MyNwind database.
BACKUP DATABASE
MyNwind TO MyNwind_2
==> MMC :
SQL Server -> Database -> Right Click ->
All tasks -> Backup Database
BACKUP options
|
INIT / NOINIT
|
NOINIT (default) appends backups to
file, INIT overwrites any existing data but retains
header information
|
|
UNLOAD (default)
|
Rewinds and unloads tape (tape drive
must locally to SQL Server)
|
|
NOUNLOAD
|
Does not rewind and unload tape
|
|
BLOCKSIZE
|
Changes physical block size
|
|
FORMAT
|
Writes new header to tape (use
MEDIANAME and MEDIADESCRIPTION)
|
|
SKIP
|
Ignores ANSI tape label
|
|
NOSKIP
|
SQL Server is reading ANSI tape
label
|
|
RESTART
|
Restarts backup from the point of
interruption
|
Types of backup methods
|
Full
backup
|
Backups Files, Objects,
date and portions of transaction
log BACKUP
DATABASE MyNwind TO MyNwind_1 |
|
Differential
Backup
|
Backs up parts of
the database since last full backup and any
uncommitted transaction in the transaction
log
==> MMC : SQL Server
-> Database -> Right Click -> All tasks
-> Backup Log BACKUP
DATABASE MyNwind TO MyNwind_1
WITH DIFFERENTIAL |
|
Transaction
Log Backup
|
-
Backs up transaction log
from last sucessfully executed BACKUP LOG
-
Requires a full database
backup for restoring
-
Truncates transaction
log
-
==> MMC
: SQL Server -> Database -> Right
Click -> All tasks -> Truncate Log
USE master
EXEC
sp_addumpdevice 'disk', 'MyNwindLog1',
'c:\mssql7\backup\MyNwindLog1.dat'
BACKUP LOG
MyNwind
TO
MyNwindLog1 |
|
Backup with
NO_TRUNCATE
|
-
Saves the entire
transaction log
-
Does not purge
transaction log of committed transactions
-
Allows recovery of data
up to the time when the system failed
WITH NO_TRUNCATE |
|
Clearing
Transaction Log
|
BACKUP LOG
northwind WITH TRUNCATE_ONLY |
Transaction Log
|
Database properties
:trunc.
log on chkpt
|
Truncate log
after checkpoint process
|
BACKUP LOG
WITH NO_LOG / TRUNCATE ONLY |
Removes
inactive part of transaction log, but doesn't back it
up
|
BACKUP LOG
WITH NO_TRUNCATE |
Backs up
transaction log without truncating
it
|
Restoring Database
Restore database
-
Recover model database first
before you recover any other database (Pointer to master
database : HKLN\software\microsoft\mssqlserver\mssqlserver\parameters)
-
Automatic recovery is done at
MSSQLServer startup
-
Specify NORECOVERY on all
backups exceptfor the last backup
-
Specify STANDBY to allow
access and to restore additionals transaction logs
Recovery Process
RESTORE DATABASE MyNwind
FROM MyNwind_1
Verify Backups
|
RESTORE
HEADERONLY
|
Returns header
information of backup file
|
|
RESTORE
FILELISTONLY
|
Returns
information about original database or transaction
log
|
|
RESTORE
LABELONLY
|
Returns
information about the backup media
|
|
RESTORE
VERIFYONLY
|
Verifies
backup files (complete and
readable)
|
Recovering
Master Database
Assuming you can still start
SQL,
-
Stop SQL Services
-
Restart SQL in single user
mode from a command prompt (SQLSERVR.EXE -m)
-
Restore Master DB using EM or
T-SQL
-
Stop SQL and restart SQL
Services
Recovering Master DB when
SQL Doesn't Start (Rebuilding Master DB)
-
Run REBUILDM.EXE from
mssql7\binn directory
-
Select sort order, character
set, and unicode collation (you will need the SQL 7.0
source files). New files for master, msdb, model,
pubs, and northwind are copied to installation.
-
Restore Master from backup;
then restore model, msdb, and distribution database (if
distribution server).
-
If no valid copy backup copy
of master exists, you must recreate logins, references to
databases, etc., in the master. You can use scripts
which you have previously generated or EM. You must
then restore databases from backup or use sp_attach_db if
the database files are present. The latter is more
efficient.
SQL Server Agent
SQL Server Agent
|
Scheduling
engine
|
Starts
scheduled jobs
|
|
Alert
engine
|
Monitors and
receives events and performs action (send email/pager,
launch job)
|
|
Event
engine
|
Log and
captures messages posted by SQL Server
|
|
Job
engine
|
Runs jobs,
write message to NT Event-Log on success or
failure
|
Alerts
-
Security-Level 19-25 are
written to NT Event-log
-
Alerts stored in
msdb..sysalerts
-
User-defined error-number must
be greater than 50000
Create Job
-
Specify properties for each
job (==> MMC : SQL Server ->
Management -> Jobs )
-
Job is stored in
msdb..sysjobs
-
Job-history stored in
msdb..sysjobhistory
-
Job owners who are not members
of sysadmin-role use security of SQLAgentCmdExec
-
SQL Agent Error are saved
under C:\mssql7\log
-
Generate Web-Page use
Wizard-> Management -> Web Assistent Wizard
-
Web Publishing stored in
msdb..mswebtasks
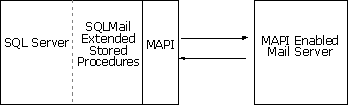
SQL Mail
-
Use messaging server that is
MAPI compliant
-
Set up e-mail client on SQL
Server
-
Configure mail profile
-
On MMC
specify mail profile for SQL Mail and SQLAgentMail
-
SQLAgentMail
-
Service from
SQLServerAgent
-
Send mail from alert, status
of a job (succeeds ...)
-
==> MMC :
SQL Server -> Management -> SQL Server
Agent -> Operators
-
Before sending mail
configure Outlook (Outlook -> Tools -> Services
-> eg Internet Mail)
-
Configure Operator (Net Send
address, E-Mail-address ...)
-
Configure Job
(==> MMC : SQL Server ->
Management -> SQL Server Agent -> Jobs)
-
SQL
Mail
-
==> MMC :
SQL Server -> Support Services -> SQL
Mail
-
Service from MSSQLServer
Service
-
Executes the xp_sendmail
stored procedure
-
Process incoming e-mail
messagesfrom SQL Mail and return result to sender
Linked
Servers
-
A pre-registered OLE DB data
source that allows local server to know where to find data
requested in a query or where to execute a stored
procedure.
-
Remote data source does not have
to be SQL, as long as an OLE DB provider exists for the
source, nor does the remote data source have to be a
relational database.
-
Replaces remote servers.
-
sp_serveroption
(with data access option set to on) allows
you to get a remote server (used in replication) to behave
like a linked server.
Linked Server Security
-
Local SQL server logs on to
linked (remote) server on behalf of user.
-
If login (and password,
depending on security mode) exist on both machines,
existing accounts used.
-
Login IDs and passwords may be
mapped between local and linked servers using
sp_addlinkedsrvlogin. Many-to-one
mappings can exist. In example below, all users who
access data on the local server are logged into linked
server as 'AnotherServer/allusers'.
EXEC
sp_addlinkedsrvlogin
@rmtsrvname='AnotherServer'
@useself='false'
@locallogin='NULL'
@rmtuser='allusers'
Setting Up Linked
Servers
sp_addlinkedserver [@server=]
'server'
[,[@srvproduct=]'product_name'
[,[provider=]'provider_name] [,[@datasrc=]'data_source]
[,[@location=]'location'] [,[provstr=]'provider_string]
[,[catalog=]'catalog]
-
If linking SQL servers, many
of these parameters unnecessary (eg, EXEC
sp_addlinkedserver 'AnotherServer' 'SQL Server')
-
If linking SQL 4.x, 6.x with
OLE DB provider, you must run INstacat.sql script on
server (not necessary if using ODBC OLE DB
provider).
-
Use
sp_dropserver to remove linked
servers
Linked Server Queries
-
By default, processed on local
server
-
Allowed T-SQL: Select with
WHERE or JOIN, INSERT, UPDATE, DELETE
-
Not Allowed T-SQL:
CREATE, ALTER, DROP
-
Query expression must use
4-part name specifying server
-
To specify processing of query
on remote server, use OPENQUERY function
SELECT * FROM
OPENQUERY
('anotherserver', 'SELECT * FROM
northwind.dbo.productinfo')
Replication
Methods for Distributing
Data
-
Replication:
Makes possible the transfer of data from a
source to a destination or destinations. Allows
for site autonomy and scalabilty. Can be used to
ensure transactional integrity without the overhead of
distributed transactions.
-
Distributed
Transactions: Transactions occur at the same
time to all copies of data on all servers involved in
the transaction. Using the 2-phase commit protocol
(2PC) ensures transactions are committed on all servers
or not at all on any. Requires good connectivity
between servers. Useful when data needs to be same
across all servers at the same time.
Terminology
-
Publisher: Makes data
available to other servers (Subscribers) for
replication. Data may be published again by
Subscribers. Data elements that are replicated
have a single publisher.
-
Distributor: Contains the
distribution database that holds metadata (system
tables) used for replication, history, and, for
transactional replication, transactions. Can be on the
same machine as Publisher or Subscriber.
-
Subscriber:
Receives updates. In some cases,
can also make updates (see below).
-
Publication:
A collection of articles for publication.
Each publication has at least one article. A
single publication can be configured for both push and
pull subscriptions.
-
Article: Grouping of
data--entire table, selected colums (vertical
filtering), selected rows (horizontal filtering), or
even a stored procedure. A publication will often
have multiple articles. Subscription is to a
publication, not an article, which was possible in SQL
6.5.
-
Push
Subscription: The Publisher initiates
the replication to the subscribers. Useful when
changes have to be sent as soon as they occur, but
replication can be scheduled.
-
Pull
Subscription: The Subscriber initiates
the replication according to a schedule. Best for
situations where there are many Subscribers. Also
best for mobile users who have the flexibility to
determine when to recieve updates. You can also
set up a special type of Pull Subscription for anonymous
users. Useful if you are publishing information to
the Internet or if you wish to reduce overhead
associated with large numbers of subscribers.
-
Horizontal
Filtering: Allows you to publish only a
subset of rows to a Subscriber. Useful when the
sites only need certain rows in the database.
Requires use of columns that can be used to identify
sites. Can be used for all replication
types. Avoid if DB is small, has low activity,
etc.,.
-
Vertical
Filtering: Allows you to publish only a
subset of columns. Not supported for Merge
Replication (however, you could simply create a table at
the publisher that only included the columns for
publication). Can be used for improving
performance by eliminating large text or image columns,
etc.,. Little impact on performance as compared to
Horizontal Filtering.
-
Fragmenting:
Allows you to partition data. For
example, 2 servers share the same table and complete
data, but each needs to update information
specific to only its region while being able to view the
data from the other region. Each server will be
both Publisher and Subscriber to the other and publish
data specific to its region and receive data from the
other in the same table. Stored procedures could
be used to ensure that each region updated its own
data. A disadvantage is the need to maintain table
schema at multiple locations.
-
Join
Filters: Available for Merge Replication
only. Allows you to include rows from other,
related tables.
-
Dynamic
Filters: Available for Merge Replication
only. Allows you to replicate a subset of data to
particular machines or users.
Replication Types
-
Snapshot
Replication: Takes a picture of the data
at a point in time. Not as CPU intensive as
Transactional Replication, which has to monitor
publications for updates. Simplest type of
replication. Guarantees latent transactional
integrity between source and destination. Good for
read-only subscribers who do not need most recent copy
of data.
-
Snapshot Replication
with Immediate-Updating Subscribers: An
optional configuration of Snapshot Replication that
allows subscribers to make changes at the subscriber and
the publisher using 2PC. Transactional integrity
is maintained between publisher and subscriber.
This method of updating the publisher requires that only
the subscriber and the publisher involved in the
transaction be enlisted for the distributed transaction,
not all the servers subscribing to the
publication. Good for situations where subscribers
have to make occasional updates to data.
-
Transactional
Replication: Used for replicating tables
(all or part of a table) and stored procedures.
The Log Reader Agent monitors the logs of publications
for INSERT, UPDATE, DELETE statements and other
modifications and then stores these modifications in a
queue, the distribution database, for replication to
subscribers. Changes are made at the publication
server, so transactional integrity is guaranteed.
Given good network connections, there can be low latency
between publisher and subscriber (less than a minute for
push subscriptions). Can also be used for pull
subscriptions where subscribers are not always connected
and require read-only data, eg., salesperson who needs
to get inventory and price lists.
-
Transactional
Replication with Immediate-Updating Subscribers: Allows subscribers to make updates to their
local data and the data on the publisher using a
distributed transaction. Transactional integrity
guaranteed using 2PC. All subscribers eventually
have transactions replicated to them from the
publisher.
-
Merge
Replication: In merge replication, both
the publisher and the subscriber update data.
The data contained in the replica copies held by
the publisher and the subscribers are the result of
synchronization (convergence). With merge
replication, there is no guarantee of transactional
integrity and conflicts between updates can arise.
SQL Server resolves conflicts based on 'generation
numbers' and configured priorities--some server will
"win" in the case of a conflict. Merge replication
guarantees that eventually all servers will converge to
the same resultant data, but the converged data may be
different from the data resulting from other forms of
replication that guarantee transactional
integrity.
Replication Agents
-
Snapshot
Agent: Used to initialize all replication
types and to perform Snapshot Replication itself.
The agent creates the schema and the data to be sent to
Subscribers. It first connects from Distributor to
Publisher and locks tables for publication (should be
run during periods of low activity because no updates
can occur in the tables during the lock). It then
connects back from Publisher to the distributor and
places schema in a .sch file and indexes (if indexes or
DRI are requested in the publication) in a .idx file on
the Distributor. The agent then takes a snapshot of the
published data and stores it in a file on the
Distributor--the file is a native .bcp (bulk copy) file
for SQL Server data sources and a .txt character mode
file if data sources other than SQL are involved in
replication. The agent then adds rows to the
MSrepl_commands table on the Distributor indicating the
location of the .sch, bcp, and .txt files
(synchronization set); it also adds rows for the
synchronization task in the MSrepl_transactions table on
the Distributor.
-
Distribution
Agent: Used for Snapshot and
Transactional Replication. For Snapshot
Replication, the agent establishes a connection from the
server it is running on to the Distributor to read the
MS_replcommands and MSRepl_transactions tables and to
move schema and data to Subscribers. For pull
subscriptions, agent runs on Subscriber; for push on the
distributor. Place the agent on a Subscriber (pull
subscription) when you have large numbers of Subscribers
to save resources on the Distributor. The
distribution agent in Transaction Replication moves
transactions (commands) stored in distribution database
to Subscribers. For push replication, the agent
runs on the distributor; for pull on the
Subscriber. (The distribution database does not
contain any user tables--don't add objects to
it.)
-
Log Reader
Agent: Used only for transaction
replication. The agent examines the transaction
logs of databases marked for replication and identifies
transactions (INSERTS, UPDATES, and so on) that need to
be replicated. It then copies transactions to the
distribution database, which acts as a store-and-forward
queue for the transactions. When the transactions
are committed in the distribution database, it updates
the original transaction logs to indicate which
transactions have been copied to the distributor and
consequently which rows can be truncated from the
original logs on the Publisher. You cannot
truncate transactions on the publisher unless they have
been committed in the distributor database. Data
that is no longer required for transactional replication
is cleaned up by 3 tasks: Agent checkup,
Transaction cleanup, and History cleanup.
-
Merge Agent:
Used for Merge Replication. The Merge
agent looks at rows in the merge article that have a
generation column value of "0". (A trigger on the
article sets the value of the generation column to 0
every time an update is performed on the row.) The
merge agent, which keeps track of generation values it
has sent to other sites and that other sites have sent
to it, assigns new generation values that are higher
than previous values. It then sends the changed data to
other sites, where the data is merged according to
configurable rules. In the case of a conflict,
which is detected through lineage values in the
MSmerge_contents table, assigned priorities determine
the "winner". (Custom resolution solutions can
also be implemented.) It is possible to view all
the rows involved with the conflict.
Replication Models
-
Central
Publisher/Distributor: Both the
Publisher and the Distributor are on the same machine
with Subscribers on separate servers.
-
Central Publisher
with Remote Distributor: Like above, except
Publisher and Distributor are on different
machines. In heavy OLTP environments, this
scenario is useful in that it reduces the load on the
Publisher. Requires good network connectivity
between Publisher and Distributor.
-
Publishing
Subscriber: In this scenario, the
Subscriber is also responsible for republishing the
received data. Useful in situations where there
is low available bandwidth between locations. For
example, you have a slow link between Vancouver and Hong
Kong. The Subscriber in Hong Kong would republish
the received data to Canberra, Sydney, Bangkok.
-
Central
Subscribers/Multiple Publishers: A number
of publishers replicate data to a common destination
table on the subscriber. The data has to be
partitioned and a primary key used to identify the
source region/server. Useful for rolling up
information.
-
Multiple
Publishers/Multiple Subscribers: Each
replicates information to and receives replicated
information from a common table. Useful for
situations where sites have to be able to view
information updated in other sites.
Any replication type can be
used with any model. The model is simply the
physical topology of your
replication.
Installing and
Configuring Replication
In order to set up
replication, you must first create a distributor.
You should use the replication wizards to install and
configure replication. Must be a member of
sysadmin role to initialize DB for publication; DBO can
then create and modify publications.
Configure Publishing
and Distribution Wizard
-
Configure server as
Publisher, choose DB for publication, and select
subscribers
-
Configure server as
Distributor and choose location for distribution DB
and log
-
Enable other servers to
use server as Distributor
-
Choose another server as
remote Distributor (must already be a
Distributor)
-
Register
Subscribers
Create Publication
Wizard
Disable Publishing
and Distribution Wizard
-
Deletes distribution DB's
on server
-
Disables all publishers
that use distributor and deletes publications
-
Deletes subscriptions, but
data on Subscribers remains.
Push Subscription
Wizard
Used to specify
-
servers to receive
publication, which must have been previously
registered by sysadmin
-
the destination database,
which must exist prior to setup
-
subscription
properties
Pull Subscription
Wizard
Used to specify
-
publication you wish to
subscribe to
-
the name of the
destination database for the subscription
-
other properties, such as
the schedule, whether the subscriber can update data,
etc.
Modifying Distributor
and Publisher Properties
Changing the distribution
database for a Publisher means starting over. You
can use the Configure Publishing and Distribution dialog
box to modify the properties for the Publisher and local
Distributor. When you remove a Publisher from the
Distributor, all subscriptions to all publications are
deleted along with the publication definitions.
Some Planning
Considerations
Depending on the type of
replication you are performing some data types must be
present or absent. If you are bypassing the
initial snapshot replication (doing a manual snapshot by
restoring a database backup, for example), you will have
to add these datatypes manually at the destination
database.
-
the
timestamp (not related to date and
time) data type must be present for immediate updating
options. It must be removed for merge
replication.
-
the
uniqueidentifier data type with the
ROWGUIDCOL property must be present for merge
replication. It will be added automatically if
it is not present.
Text,
ntext,
and image datatypes can be
replicated only with snapshot replication. (It is
possible to control the maximum size of these datatypes
that will replicate with snapshot
replication.)
The replication process will
not replicate the IDENTITY property on a column, but
will replicate values in the column. If the
property itself were replicated, values might be
reseeded at the subscriber.
The NOT FOR REPLICATION
property is useful in partitioned environments that are
using the identity property on columns. This
option allows control over the range of values for
seeded identity values.
Ensure adequate diskspace
exists at the distributor for snapshot or transactional
replication. If using push subscriptions, ensure
that distributor can handle extra load; otherwise,
use pull or anonymous subscriptions.
If using transactional
replication and a very large number of rows are affected
by a transaction, consider replicating a stored
procedure instead (be careful with this kind of
replication, since transactional integrity could be
compromised).
For fault tolerance, do
backups and create scripts based on replication
configuration.
Monitoring and
maintaining SQL Server
Tools for monitoring SQL
Server
-
Microsoft Event Viewer
(Start -> Programs -> Administrative Tools
-> Event Viewer)
-
Performance Monitor
(Start -> Programs -> Microsoft SQL Server
7.0 -> Performance Monitor)
-
SQL Server Profiler :
A SQL Server tool that captures a continuous
record of server activity in real-time. SQL Server
Profiler can monitor many different server events and
event categories, filter these events with user-specified
criteria, and output a trace to the screen, a file, or
another SQL Server.
-
SQL Query Analyzer :
Show Estimated Execution Plan
-
dbcc commands :
The Transact-SQL programming language provides
DBCC statements that act as the “database consistency
checker” for SQL Server. These statements check the
physical and logical consistency of a database. Many DBCC
statements can fix detected problems.
-
sqlmaint.exe :
The sqlmaint utility performs a specified set of
maintenance operations on one or more databases. Use
sqlmaint to run DBCC checks, back up a database and its
transaction log, update statistics, and rebuild indexes.
All database maintenance activities generate a report that
can be sent to a designated text file, HTML file, or
e-mail account.)
-
sp_who :
Provides information about current SQL Server users
and processes
-
sp_lock :
Reports information about locks
-
sp_monitor :
Displays statistics about SQL Server
-
sp_spaceused :
Displays the number of rows, disk space reserved,
and disk space used by a table in the current
database
-
MMC : SQL
Server -> Management -> Current Activity (Process
Info, Locks)
-
MMC : SQL
Server -> Management -> Replication Monitor ->
Replication Alerts
-
MMC : SQL
Server -> Management -> SQL Server Logs
SQL Server
Configuration
Use sp_configure
to see a list of configuration options. To see
advanced sp_configure options, use the
'Show Advanced Options' option.
Some Relevant Tuning
Options:
-
Max Worker
Threads: Default is 255. If SQL
needs more than this no. of threads, it will start
sharing threads (thread pooling). For small
numbers of users, less than 255 is better than default
value.
-
Parallel Query
Options (Max Degree of Parallelism,
etc.,): When turned on, can allow all or
a subset of processors in a multi-processor machine to
be used for a query. Should be used with care,
because it can have a detrimental affect on
performance. Use when few users are
connecting. Can be set through EM.
-
Min Server
Memory: Sets a minumum amount of memory
that SQL will use on start up.
-
Min Memory Per
Query: Sets a minimum amount of memory
for each query a user runs. On large OLAP servers,
this setting might be useful.
-
Max Server
Memory: Sets max amount of memory that
SQL will use.
-
Max Async
IO: Default is 32. When you have an
efficient disk subsystem using multiple channels,
increasing this value may be beneficial. Look at
the disk queue length Performance Monitor Counter.
Optimally, this value should be less than 2.
Log-Files
|
Log
|
Location
|
Description
|
|
sqlstp.log
|
C:\winnt\sqlstp.log
|
Logging
information about SQL Server setup
|
|
SQL Server
error log
|
C:\mssql7\log\errorlog
|
Records
information about startup of SQL Server
|
|
SQL Server
inst.-log
|
C:\mssql7\install\cnfgsvr.out
|
Log-file for
installation
|
Tools
|
odbcping
|
Ping to
Database
|
|
isql
|
SQL Server
Query analyzer (DB-library, tool from pervious
version)
|
|
osql
|
SQL Server
Query analyzer (ODBC)
|
|
sqldiag
|
|

